����(li��n)�Ϙ�(bi��o)ע��ȫ��������ƪ�¼�(j��)�¼���ȡ
�r(sh��)�g��2020��03��11�� �����(j��ng)��(j��)Փ�� �Δ�(sh��)��
����ժҪ���¼���ȡ���Ԏ����˂��ĺ������ı��п��١���(zh��n)�_�ث@ȡ���dȤ���¼�֪�R(sh��)��Ȼ����Ŀǰ�¼���ȡ���о���Ҫ�����ڏĆ�һ�����г�ȡ�¼�.�����¼���(g��u)�ɵď�(f��)�s�Ժ��Z�Ա����Ķ����ԣ�����(sh��)��r�¶���������������һ��(g��)�¼�����ˣ���ƪ���г�ȡ�������ĽY(ji��)��(g��u)���¼���Ϣ���@�ø��Ѓr(ji��)ֵ�����x��ԓ���������û���ע�����C(j��)�Ƶ����И�(bi��o)עģ��(li��n)�ϳ�ȡ���Ӽ�(j��)�¼����|�l(f��)�~�͌�(sh��)�w���c��(d��)���M(j��n)�Ќ�(sh��)�w��ȡ���¼��R(sh��)�e��ȣ�(li��n)�Ϙ�(bi��o)ע�ķ�����Fֵ��������1��(g��)�ٷ��c(di��n)��Ȼ�����ö��Ӹ�֪�C(j��)�Д���(sh��)�w���¼��а��ݵĽ�ɫ������ھ��Ӽ�(j��)�¼���ȡ�Ļ��A(ch��)�ϣ���������(sh��)����Ҏ(gu��)���ķ������M(j��n)��ȫ������.�ںϾ��Ӽ�(j��)�¼���Ϣ����(sh��)�F(xi��n)ƪ�¼�(j��)�¼���ȡ.�c����ģ�����.�@�N����ȫ��������ƪ�¼�(j��)�¼���ȡ��Fֵ��������3��(g��)�ٷ��c(di��n)��
�����P(gu��n)�I�~��ƪ�¼�(j��)�¼���ȡ;(li��n)�Ϙ�(bi��o)ע;ȫ������
����o����
������(d��ng)�����(hu��)����(li��n)�W(w��ng)�ѳɞ�����ճ������в��ɻ�ȱ��һ���֣��ڞ��˂�������W(xu��)��(x��)����������O���ͬ�r(sh��)����(li��n)�W(w��ng)�к����ķǽY(ji��)��(g��u)���ı�Ҳ�o�Ñ���Ϣ���������_���挦(du��)�������L(zh��ng)�ķǽY(ji��)��(g��u)���ı���(sh��)��(j��)����Ύ����˂����Ⲣ���٫@ȡ�ı��е�֪�R(sh��)���@���Ȟ���Ҫ������Ϣ��ȡ���g(sh��)��������Ǟ��˽�Q�@��(g��)���}��������Ȼ�Z��̎��(NaturalLanguageProcessing,NLP)���g(sh��)�е��P(gu��n)�I�΄�(w��)����Ϣ��ȡ��֪�R(sh��)�@ȡ�а�������Ҫ�Ľ�ɫ��Grishman�ȢŌ���Ϣ��ȡ���x�飺����Ȼ�Z���ı��г�ȡָ����͵Č�(sh��)�w���P(gu��n)ϵ���¼�����(sh��)��Ϣ�����γɽY(ji��)��(g��u)����(sh��)��(j��)ݔ�����ı�̎�����g(sh��)��������ǽY(ji��)��(g��u)���ı����¼���ȡ����Ϣ��ȡ�I(l��ng)���е��P(gu��n)�I�΄�(w��)����Ҫ���о�����(����߀�Ќ�(sh��)�w��ȡ���P(gu��n)ϵ��ȡ��)����Ҫ��(y��ng)�����¼�֪�R(sh��)�D�V�Ę�(g��u)�����¼���Ϣ�@ȡ���o��������Ȼ�Z�������΄�(w��)��
�����¼��ǂ�(g��)��(f��)�s�ĸ���ڲ�ͬ�о��I(l��ng)���в�ͬ�Ķ��x���¼���ȡ�I(l��ng)�������Ӱ������u(p��ng)�y(c��)��(hu��)�h----�Ԅ�(d��ng)��(n��i)�ݳ�ȡ(AutomaticContentExtrac-non,ACE®)�u(p��ng)�y(c��)��(hu��)�h���¼����x�飺�¼��ǰl(f��)����ij��(g��)�ض��r(sh��)�g��r(sh��)�g�Ρ�ij��(g��)�ض�������(n��i)����һ��(g��)�����(g��)��ɫ���c��һ��(g��)�����(g��)��(d��ng)����(g��u)�ɵ�������B(t��i)�ĸ�׃���¼��е����P(gu��n)�g(sh��)�Z���w���x���£���(sh��)�w(entity)���Ñ����dȤ���Z�x��(du��)��.ͨ����һ��(g��)���~(���磬“����”);�¼��|�l(f��)�~(eventtrigger):�|�l(f��)�¼��ĺ����~��ͨ���DŽ�(d��ng)�~�������~(���磬“����”��“���u”);�¼�Ԫ�ؽ�ɫ(eventargument):��(sh��)�w���¼��������ݵĽ�ɫ•���¼��ą��c��;�¼�����(eventmention):�����¼���һ��Ԓ����һ��(g��)�ֶΣ�ͨ����(hu��)�����|�l(f��)�~���¼�Ԫ��;�¼�e(eventtype)���¼��|�l(f��)�~���¼���ɫ��ͬ�Q�����¼���e��
�����¼��|�l(f��)�~�͌�(sh��)�w�����M(j��n)���������(bi��o)ӛ�����������ֶδ��팍(sh��)�w����e(���磬“10��31̖(h��o)”•�r(sh��)�g)���Ӵ��ֶδ����|�l(f��)�~�����¼�e(“����”������)��̓���B���|�l(f��)�~�͌�(sh��)�w.���������ִ��팍(sh��)�w��ԓ�¼��������ݵĽ�ɫ���ڱ���(sh��)���У�“����”�|�l(f��)һ��(g��)�����¼���T0��31̖(h��o)”“�҈@�������H�C(j��)��(ch��ng)”“82��”��ԓ�¼��зքe���ݕr(sh��)�g�����c(di��n)���ܺ��ߵ��¼���ɫ.�Ķ��M��һ��(g��)�������¼�������(sh��)�w“�¼��º���”��ԓ�¼��в������κν�ɫ����ACE���¼��Ķ��x���D1��(sh��)���ɵã��¼��ĽM��Ҫ����Ҫ�����¼��İl(f��)���r(sh��)�g�����c(di��n)���¼��ą��c��ɫ�Լ��c֮���P(gu��n)�Ą�(d��ng)�����B(t��i)(�|�l(f��)�~)���ڬF(xi��n)��(sh��)������.ÿ�춼�и�ʽ���ӵIJ�ͬ��(ch��ng)������ͬ��͡���ͬ���ȵ��¼��l(f��)������Ϣ�������ӻ���ͬ�r(sh��)Ҳ�o�¼���ȡ�΄�(w��)�����y�ȡ�
����������Ȼ�Z��̎���о�������(zh��n)���΄�(w��)���¼���ȡ��Ҫ�о���ΏķǽY(ji��)��(g��u)�����ı���Ϣ�г�ȡ���Ñ����dȤ���¼������ԽY(ji��)��(g��u)������ʽ�ʬF(xi��n)������Ŀǰ�¼���ȡ���о���Ҫ�����ڃɂ�(g��)���΄�(w��)�ϣ��¼��R(sh��)�e���¼�Ԫ���R(sh��)�e���¼��R(sh��)�e���R(sh��)�e�ı��е����¼��|�l(f��)�~����(d��o)���¼���(sh��)����������(j��)��(d��ng)ǰ�|�l(f��)�~����������Ϣ�Дஔ(d��ng)ǰ�|�l(f��)���A(y��)���x�¼���͡��¼�Ԫ���R(sh��)�e����ij�䱻�ж����ض��¼���͵��¼����������Д���Ќ�(sh��)�w���¼��|�l(f��)�~֮�g���P(gu��n)ϵ���@����P(gu��n)ϵ���錍(sh��)�w��ԓ�¼��������ݵĽ�ɫ�������¼���ȡ���x��Ҫ��ᘌ�(du��)���Ӽ�(j��)�e�ģ����F(xi��n)�е��¼���ȡ��ܰ����ı����ȿɷ֞���Ӽ�(j��)�¼���ȡ��ƪ�¼�(j��)�¼���ȡ�����Ӽ�(j��)�¼���ȡ���c(di��n)�������R(sh��)�e������ÿ��(g��)�~�����ἰ�Ć�(g��)�¼�.�Լ��Д���ӌ�(sh��)�w��ԓ�¼��а��ݵĽ�ɫ���mȻ���Ӽ�(j��)��ȡ���]���¼�������ͨ��(ACE2005�ж��x��33�N�¼�)������(du��)�ڿ��Y(ji��)�ęn��(n��i)�݁��f�����Ӽ�(j��)��ȡ����̫��(x��)�ˡ��F(xi��n)��(sh��)��(ch��ng)���У�һƪ�ęnͨ������һ��(g��)���߶���(g��)�¼����@Щ�¼���(du��)�����w����Ҫ�Ը�����ͬ.��ͬһ�¼�Ҳ���ܕ�(hu��)���ęn�б�����ἰ��
����ƪ�¼�(j��)�¼���ȡ���ı�����������Ҫ�¼������ģ��ú�(ji��n)�����Y(ji��)��(g��u)������ʽ�ʬF(xi��n)�o�Ñ������ڬF(xi��n)��(sh��)������ֱ�������Ñ�Ҳ�������@���m���ԣ������S�Ñ����٫@ȡ�ęn�е��¼���(n��i)�ݡ����c(di��n)�͕r(sh��)�g��������Ҫͨ�xȫ�ġ��y�c(di��n)���ڣ�ƪ���¼���ȡ��Ҫ���|(zh��)���ľ��Ӽ�(j��)��ȡ�Y(ji��)���Լ���ͬ�¼���ͬ�¼�����֮�g�¼�Ԫ�ص��ںϣ����]�������䣺��1������(j��)�W�����Ȟ�(z��i)�M���Ľy(t��ng)Ӌ(j��)���ڰ�����˹ɽ��ɽ�|܇ʧ��K������155���˿͆�������2���W����һ̎��ѩ�ٵصĵ�ɽ�|܇11̖(h��o)�ڰ�����˹ɽ�����l(f��)���|܇ʧ��K��.�ܺ����а�����1999������Ů�ӻ�ʽ��ѩ��܊ʩ���ء���1����2������ͬһ��(z��i)�y�¼��IJ�ͬ���ӣ��ֲ���ԭ�ęn�в�ͬ�Ķ��䮔(d��ng)�С���1�а���ԓ��(z��i)�y�¼��������˔�(sh��)���¹ʁ�Դ����2�а����¼��l(f��)���ĕr(sh��)�g�͵��c(di��n)���¼�������1����2�еĽY(ji��)��(g��u)���¼���Ϣ��Ҫ�ںϲ��ܵõ�������ƪ�¼�(j��)�¼���Ϣ��ƪ�¼�(j��)�¼���ȡ��ه�ھ��Ӽ�(j��)��ȡ�Y(ji��)���Ϳ���ӵ��¼�Ԫ���ںϡ�
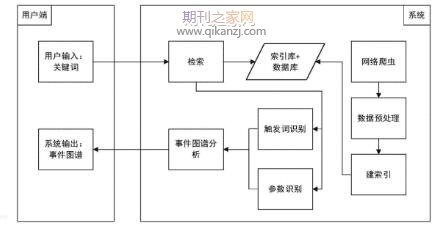
��������Փ���l(f��)�����˫@ȡƪ�¼�(j��)�¼��ĽY(ji��)��(g��u)����Ϣ����Ҫ���Ӽ�(j��)�¼���ȡ�Y(ji��)�����¼���ָ�P(gu��n)ϵ�ДࡣĿǰᘌ�(du��)ƪ���¼���ȡ�о��^�٣�߀�]�нy(t��ng)һ�Ľy(t��ng)Ӌ(j��)�W(xu��)ģ����ƪ����ֱ�ӳ�ȡ��ƪ�µ��¼���Ϣ���෴�����Ӽ�(j��)�¼���ȡ���о���څ���죬�ھ��Ӽ�(j��)��ȡ�Y(ji��)���Ļ��A(ch��)���M(j��n)��ȫ���Ɣ����ƪ���¼���ȡ�����w�����DZ����о��ķ����IJ��ùܵ�(Pipeline)�ķ�����ƪ�¼�(j��)��ȡ���}�֞�3��(g��)�ӆ��}�����������И�(bi��o)עģ�͌�(du��)�����M(j��n)�Ќ�(sh��)�w���¼���(li��n)�Ϙ�(bi��o)ע;�ڲ��ö��Ӹ�֪�C(j��)��(du��)�¼������еČ�(sh��)�w�M(j��n)�з���Д���(sh��)�w��ԓ�¼��������ݵĽ�ɫ;�ۻ�������(sh��)����Ҏ(gu��)����ȫ���������õ�ƪ�¼�(j��)�Y(ji��)��(g��u)���¼���Ϣ��������(g��)���̈D�в�������(bi��o)ע�Z���е�������Ϣ���ⲿ�YԴ��
�������ā��f�����ĵ�ؕ�I(xi��n)��������3�c(di��n)��(1)����ˌ�(sh��)�w���¼���(li��n)�Ϙ�(bi��o)עģ��.��ģ�Ϳ��Ը��õ������������еČ�(sh��)�w���¼������ه�P(gu��n)ϵ��(2)�����������(sh��)����Ҏ(gu��)���ķ����M(j��n)��ȫ�������õ�ƪ���¼���ȡ�Y(ji��)����(3)��ACE2005�����Z�����M(j��n)�Ќ�(sh��)�(y��n)����(sh��)�(y��n)�Y(ji��)���(y��n)�C��ģ�͵���Ч�ԡ�
����1����
������������ѽ�(j��ng)�C������(j��ng)�W(w��ng)�j(lu��)��������Ȼ�Z��̎���I(l��ng)�����Ч�ԡ�Zeng��Chen�Ȣ����Ȍ���ȌW(xu��)��(x��)�ķ�����(y��ng)�����P(gu��n)ϵ��ȡ���¼���ȡ�У���ȡ���˺ܺõ�Ч��������(du��)�ڂ��y(t��ng)������ʾ�ķ�ʽ����(j��ng)�W(w��ng)�j(lu��)���~����(Wordembedding)����ݔ�룬�����˂��y(t��ng)������ȡ�^���^����ه�~�Ԙ�(bi��o)ע���䷨��������Ȼ�Z��̎�����ߡ��ڱ���(ji��)�У��҂�����B����ƪ�¼�(j��)�¼���ȡ��ȡ�ķ�������Ҫ������(sh��)�w���¼�(li��n)�Ϙ�(bi��o)ע���¼�Ԫ���R(sh��)�e��ȫ��������
����1.1��(sh��)�w���¼�(li��n)�Ϙ�(bi��o)ע
������(sh��)�w���¼��Ǿo���P(gu��n)(li��n)�ģ����ߵı�ʾ���ه�����F(xi��n)�е��¼���ȡͨ������(du��)��(sh��)�w���¼��քe��ģ����Ŀǰ�¼���ȡ�΄�(w��)��.�о���һ�㌢�¼���ȡ�֞�3�����ٌ�(sh��)�w�R(sh��)�e�������ⲿ�����߆�һģ�ͳ�ȡ���еČ�(sh��)�w;���¼��R(sh��)�e����ȡ���е��|�l(f��)�~���Д��¼����;��Ԫ�ط���Д���(sh��)�w���¼��а��ݵĽ�ɫ����(sh��)�w�R(sh��)�e���¼��R(sh��)�e���_̎���dz��õļ��g(sh��)�ֶΣ�����(hu��)���Ԍ�(sh��)�w���¼��|�l(f��)�~֮�g���ه���P(gu��n)ϵ��
�������磬������“�W���R�x�_�m��ӭ���µ�����(zh��n)”�У�“�x�_”�����|�l(f��)�~���|�l(f��)��һ��(g��)�xe���¼��������\(y��n)ݔe���¼���ֻ����“�x�_”һ�~����(hu��)�������x��������֪����������(sh��)�w����e��(“�m���M���C(j��)��(g��u)”;“�W���R������”)�������Д�“�x�_”�|�l(f��)�x�¼�;�෴����(d��ng)��֪“�x�_”�|�l(f��)�x�¼��������Д�“�m”�Č�(sh��)�we�ǽM���C(j��)��(g��u)�����ǵ���λ�á������Ч���Ì�(sh��)�w���¼��|�l(f��)�~�������P(gu��n)ϵ���DZ������(li��n)�Ϙ�(bi��o)עģ�͵ij��l(f��)�c(di��n)��
�������IJ������И�(bi��o)עģ�͏ľ���(li��n)�Ϙ�(bi��o)ע��(sh��)�w���|�l(f��)�~��ͬ�r(sh��)�Д�������e���������ȡ�Y(ji��)�������¼�Ԫ�ؘ�(bi��o)ע��ݔ�롣���˸��õؽ�ģ�����ĵ��P(gu��n)(li��n)�P(gu��n)ϵ.�҂�����ע�����C(j��)��(self-attention)M�ӵ�ģ���С�Ŀǰ�кܶ�y(t��ng)Ӌ(j��)�W(xu��)��(x��)�������Ԍ�(du��)�����ı��е��~�M(j��n)���R(sh��)�e������������~����ݔ����Ҫ�Ƚ����ⲿ���~����.�����И�(bi��o)ע�����܉�ܺõؽ�Q�����~�g�o�g���Ć��}������Ȼ�Z��̎���У��ܶ���A(ch��)���}�����������И�(bi��o)עģ�ͽ�Q���������ķ��~���~�Ԙ�(bi��o)ע�Լ�������(sh��)�w�R(sh��)�e�ȡ����И�(bi��o)ע���H�ܲ��@�~��߅�磬ͬ�r(sh��)Ҳ�����Дஔ(d��ng)ǰ�~�Ěw��e��
������ͬ���ı�������И�(bi��o)עģ�͌�ݔ��ľ��ӿ���һ��(g��)���У�ݔ����һ��(g��)���L(zh��ng)�ķ�̖(h��o)���У�ÿ��(g��)��̖(h��o)��(du��)��(y��ng)�ض��ĺ��x�����w���v�����И�(bi��o)עģ�ͽo�����е�ÿ��(g��)�ַ�����BIO�Ę�(bi��o)����B��ʾ�ֶ��_ʼ(beginning),1��ʾ�ֶ����g(inside),0��ʾ�����ֶ�(outside),��(bi��o)���������type��ʾ�ֶεķ�Y(ji��)��������.B-PER��ʾ��������ʼ�ַ���I-Attack��ʾ�|�l(f��)�����¼��~�����g�ֶΡ��S����ȌW(xu��)��(x��)����Ȼ�Z��̎���еđ�(y��ng)����څ���죬������(j��ng)�W(w��ng)�j(lu��)�ķ�����ʾ�ַ��������ܸ��õز��@���Լ������ĵ���Ϣ��
��������(j��ng)�W(w��ng)�j(lu��)�У�Ŀǰ�����ăɂ�(g��)������ѭ�h(hu��n)��(j��ng)�W(w��ng)�j(lu��)(RecurrentNeuralNetworks,RNN)�;��e��(j��ng)�W(w��ng)�j(lu��)(ConventionalNeuralNetworks,CNN)�����֮�£�RNN��CNN���m�Ͻo�����M(j��n)�н�ģ����?y��n)�RNN���[�Ӽ��Ю�(d��ng)ǰ�r(sh��)�̵�ݔ�룬Ҳ��ǰһ�r(sh��)�̵��[��ݔ�����@ʹ������ͨ�^ѭ�h(hu��n)�����B�ӿ���ǰ�����Ϣ������߀�߂�Ǿ��ԵĔM���������������RNN��(du��)���е����еĽ�ģ��NLP�г��õ��ֶΡ����L(zh��ng)����ӛ���W(w��ng)�j(lu��)(LongShort-TermMemory,LSTM)�܌��^ȥ�͌��������п��]�M(j��n)��.ʹ����������Ϣ��ֱ����Þ顣��LSTM�����l���S�C(j��)��(ch��ng)(ConditionalRandomFields,CRF)�ܸ���ؿ��]����(g��)���ӵľֲ������ľ��Լә�(qu��n)�M�ϣ�Ӌ(j��)��(li��n)�ϸ��ʣ���(y��u)��������(g��)���С�ͬ�r(sh��).�҂�����ע�����C(j��)�Ƽӵ�ģ���У���ҪĿ���njW(xu��)��(x��)���Ӄ�(n��i)���ַ�֮�g����ه�P(gu��n)ϵ�����@���ӵă�(n��i)���Y(ji��)��(g��u)���Z�x��Ϣ��
����1.2�¼�Ԫ���R(sh��)�e
�����ęn��ÿ��(g��)���ӽ�(j��ng)�^�����Č�(sh��)�w���¼�(li��n)�Ϙ�(bi��o)ע�ɫ@�þ��еČ�(sh��)�w���䌍(sh��)�w��ͺ��¼��|�l(f��)�~�����¼���͡���õ����Ӽ�(j��)���¼��Y(ji��)��(g��u)����Ϣ����Ҫ�M(j��n)һ����(bi��o)ע��(sh��)�w���¼��а��ݵĽ�ɫ������(sh��)�w���|�l(f��)�~֮�g���P(gu��n)ϵ(��Ů�ڣ��Єe��(sh��)�w“155���˿�”��“����”�¼�����а�����“�ܺ���”�Ľ�ɫ)�����˳�����Ì�(sh��)�w�����;����е��¼���Ϣ����������һ��(g��)���Ӹ�֪�C(j��)��(sh��)�F(xi��n)��(sh��)�w�ķ�Ķ���(sh��)�F(xi��n)�¼�Ԫ���R(sh��)�e��ݔ�����������|�l(f��)�~���|�l(f��)�~e����(sh��)�w����(sh��)�we����(sh��)�w���|�l(f��)�~֮�g��λ����Ϣ�Լ���(d��ng)ǰ����ͨ�^LSTM����������ʾ��
����1.3ȫ������
�������ęn�ı��У���Ҫ���¼�ͨ����(hu��)������ἰ����ͬһ�¼���(hu��)�ж���(g��)�¼���������(j��ng)�^�������Ӽ�(j��)�¼���ȡ���ɫ@��ƪ���е�һϵ�нY(ji��)��(g��u)���¼���Ϣ����@��ƪ�¼�(j��)���¼���Ϣ����Ҫ�Д����(g��)�¼������Ƿ�ָ��ͬһ�¼����Ķ��õ��������¼���Ϣ���¼�������1����2�քeͨ�^“����”��“�ܺ�”�|�l(f��)“����”�¼���ͣ�ͨ�^�ı����������Ƴ̶ȿ����M(j��n)һ���Д���1����2ָ����ͬһ�¼����Ķ������ߵ��¼�Ԫ���M(j��n)���ںϵõ�ƪ�¼�(j��)���¼��Y(ji��)��(g��u)����Ϣ�����˳�������ı���Ϣ�M(j��n)���¼���ָ���Д࣬���IJ�������(sh��)����Ҏ(gu��)���ķ����M(j��n)��ȫ�����������@ȡ���õ��¼���ָ�Д����郞(y��u)��Ŀ��(bi��o)�����ı����ƶ����郞(y��u)��Ŀ��(bi��o)����Ҫϵ��(sh��)���ڗl���s���£��õ�ƪ�¼�(j��)�¼���ȡ���(y��u)�Y(ji��)����
����2ģ��
��������(ji��)��Ҫ��B�����������õ�ģ�ͣ�����������ע�����C(j��)�ƵČ�(sh��)�w�¼�(li��n)�Ϙ�(bi��o)עģ�͡����ڸ�֪�C(j��)���¼�Ԫ���R(sh��)�eģ�ͺͻ�������(sh��)����Ҏ(gu��)����ȫ��������
����3��(sh��)�(y��n)
����3.1��(sh��)��(j��)
������������ACE�u(p��ng)�y(c��)�l(f��)���Ĺ��_�Z��ACE2005�е������Z�����錍(sh��)�(y��n)��(sh��)��(j��)������(sh��)��(j��)���И�(bi��o)ע�Č�(sh��)�we������PER(Person,����)��ORG(Organization,�M���C(j��)��(g��u))��GPE(Geo-PoliticalEntity,���λ����ĵ���^(q��)��)��LOC(Location������λ��)��FAC(Facility,�����O(sh��)ʩ�Ĉ�(ch��ng)��),VEH(Vehicle,�\(y��n)ݔ����),WEA(Weapon,����)�Լ�VALUE(ֵ)��TIMEC�r(sh��)�g)��ACE2005���A(y��)���x33��(g��)�¼���e��ÿ��(g��)�¼�e���ɲ�ͬ���¼���ɫ��(g��u)�ɡ����ą���Chen��Ji���M(j��n)�Д�(sh��)��(j��)�Ą��֕r(sh��),����569/64/64/ƪ�ęn�քe������Ӗ(x��n)����/�y(c��)ԇ��/�(y��n)�C��������P(Precision,���_��)��R(Recall,�ٻ���)����ֵ�u(p��ng)�r(ji��)���Ӽ�(j��)�Č�(sh��)�w��ȡ���¼��R(sh��)�e���ܡ�����Reichart�Ȣ˲��õ�ƪ�¼�(j��)�¼���ȡ�u(p��ng)�r(ji��)��ʽ����(du��)��ÿƪ�ęn�����W(xu��)��(x��)���ĽY(ji��)��(g��u)���¼���Ϣ�͘�(bi��o)��(zh��n)�M(j��n)�����ƥ�䣬Ȼ������P��R��F,�M(j��n)��ƪ�¼�(j��)�¼���ȡ���ܵ��u(p��ng)�y(c��)��
����3.2����(sh��)
����ģ�͵�һЩ��(sh��)�F(xi��n)��(x��)��(ji��)���£�ݔ���embedding��100�S���~��������ͨ�^�ھS���ٿ������Z���M(j��n)���A(y��)Ӗ(x��n)���õ��ġ�LSTM�[�ӾS�Ȟ�200,batch�O(sh��)����50,�W(xu��)��(x��)�ʞ�0.000l,droupout��0.5.��K����Adam���郞(y��u)������
����4���P(gu��n)�о�
������(d��ng)ǰ�¼���ȡ�����о������ɷ֞�ɴ������ģʽƥ��ͻ��ڽy(t��ng)Ӌ(j��)ģ�͡�ģʽƥ��ķ������ض��I(l��ng)����ȡ���^�õľ��_�ȣ����͵Ļ���ģʽƥ����¼���ȡϵ�y(t��ng)�У�ExDisco[l0]��FSA^����ԓ������Ҫ�����˹��M(j��n)��ģ�������������m�Բֻ�m����СҎ(gu��)ģ���ض��I(l��ng)���ڽy(t��ng)Ӌ(j��)�W(xu��)��(x��)�ķ������������xȡ���ֿɷ֞������ڂ��y(t��ng)�����xȡ�ͻ�����(j��ng)�W(w��ng)�j(lu��)�Ԅ�(d��ng)�W(xu��)��(x��)���������y(t��ng)������ȡ��Ҫͨ�^��Ȼ�Z��̎�����߫@ȡ���N��Ч���~�R���䷨���Z�x��������Ȼ�����Â��y(t��ng)���ģ��(���磬���ģ�ͺ�֧�������C(j��)ģ��)�M(j��n)�з��"“�����S����ȌW(xu��)��(x��)�C��������NLP�е���Ч��,Chen�Ȣ����Ȍ�CNN��(y��ng)�õ��¼���ȡ�У��������˾��x��Ϣ����ģ��(sh��)�w���|�l(f��)�~��λ���P(gu��n)ϵ;Nguyen�ȡ������һ�N����RNN��ģ���M(j��n)���¼��R(sh��)�e�ͽ�ɫ���(li��n)�όW(xu��)��(x��)��
����ᘌ�(du��)�Z��ȱ����ƽ��Ȇ��}��Liu�Ƚ����ⲿ�Z�x�YԴ�M(j��n)���¼��R(sh��)�e;Chen�������h(yu��n)�̱O(ji��n)���ķ����U(ku��)��Ӗ(x��n)���Z��������¼���ȡ����;Yang�ȡ�������ƪ����Ϣ�M(j��n)���¼��͌�(sh��)�w��(li��n)�ϳ�ȡ��������֞�3��(g��)�ӆ��}���W(xu��)��(x��)�¼���(n��i)���Y(ji��)��(g��u)���W(xu��)��(x��)�¼��c�¼��P(gu��n)ϵ���W(xu��)��(x��)��(sh��)�w��ȡ;Uu�Ȣš������p�Z�YԴ����¼���ȡ�����ܡ��@Щ������Ӣ���¼���ȡ��(sh��)��(j��)����ȡ���˺ܺõ�Ч���������¼���ȡ���棬�~��(j��)�IJ�ƥ�䆖�}��(y��n)��Ӱ��˝h�Z��Ϣ��ȡ���~��(j��)ģ�͵����ܡ����˽�Qԓ���},Chen��Ji�Ȣ�����˻����������ַ���(j��)BI()��(bi��o)ע;Li�ȡ��Ӷ��x�������|�l(f��)�~���˹�ģ�壬�@Щ�������߶���ه���˹���(g��u)����ģ������������ı����ȿ���Ŀǰ�¼���ȡ�����P(gu��n)�о���Ҫᘌ�(du��)���Ӽ�(j��)�e�ij�ȡ.���R(sh��)�e�����|�l(f��)�~�����Д���(sh��)�w���¼��������ݵĽ�ɫ�����F(xi��n)��(sh��)������ı��������ƪ�µ���ʽ���F(xi��n)���Ñ����P(gu��n)�ĵ��Ǐ�ƪ���Ы@�ýY(ji��)�������¼�֪�R(sh��)��
����������¼���ȡϵ�y(t��ng)FRUMPY]�����¼�ģ��ƥ��ķ����M(j��n)��ƪ���¼���ȡ��Huang�Ȳ��û���ģʽ��ķ�������ƪ�³�ȡ���Ƀɂ�(g��)�ӆ��}���ٽ�ɫ�����;�ھ����P(gu��n)(li��n)ģ�͡�Yang��[�A���û��ھ��ӳ�ȡ�Y(ji��)���Լ��ı������l(f��)�F(xi��n)���¼�������������������Ԫ���a(b��)�R���Եõ�ƪ���¼��Y(ji��)��(g��u)����Ϣ�ķ����������Ľ����¼���ȡ��(sh��)��(j��)����ȡ�ò��e(cu��)��Ч�������ā��f��Ŀǰƪ���¼���ȡ���о���Ҫ�������ض����I(l��ng)�߶���ه�˹�Ҏ(gu��)�t�����y�ƏV���µ��I(l��ng)�����Ӽ�(j��)�¼���ȡ������(y��ng)���ڸ��V�����I(l��ng)�����ɵ�ݔ������̫��(x��)���o���ṩ�õ��ęn��(j��)�¼���Ϣ��
����5���Y(ji��)��չ��
��������ӑՓ���¼���ȡ��(du��)��֪�R(sh��)�@ȡ����Ҫ�ԣ����U���˾��Ӽ�(j��)�¼���ȡ��ƪ�¼�(j��)�¼���ȡ�IJ����Ⱦ��Ӽ�(j��)�¼���ȡ�ļ�(x��)���ȽY(ji��)����ƪ�¼�(j��)�¼���ȡ�ĽY(ji��)���ܷ�ӳ���������¼���Ϣ�����и��õĬF(xi��n)��(sh��)���x�͌�(sh��)�Ãr(ji��)ֵ�����ˏ��ı��Ы@ȡƪ�¼�(j��)�¼���Ϣ�����IJ�����ȌW(xu��)��(x��)�ķ�����ȡ���Ӽ�(j��)�¼���Ϣ����ģ���Ƀɲ��ֽM�ɣ��������И�(bi��o)ע���¼���(sh��)�w(li��n)�ϳ�ȡ�ͻ��ڶ��Ӹ�֪�C(j��)���¼�Ԫ���R(sh��)�e���ھ��Ӽ�(j��)�¼���ȡ���A(ch��)�ϣ���ȡ����(sh��)����Ҏ(gu��)���M(j��n)��ȫ���Ɣ�õ�ƪ�¼�(j��)�¼��Y(ji��)��(g��u)����Ϣ��������ACE2005��(sh��)��(j��)���ϵČ�(sh��)�(y��n)�Y(ji��)���C���˷�������Ч�ԡ�Ȼ��������Pipeline�ķ������ɱ���ؕ�(hu��)�����`��Ă��f��������ö˵��˵�ģ��.��ƪ���ı���ֱ�ӳ�ȡ���¼��Y(ji��)��(g��u)����Ϣ������ƪ�¼�(j��)�¼���ȡ���w���ܣ�����һ����Ҫ�о�����̓�(n��i)�ݡ�
�������P(gu��n)Փ�ķ��ģ���(sh��)��(j��)�ڌ�Ӌ(j��)���������еđ�(y��ng)���о�
����ժҪ��21���o(j��)�����罛(j��ng)��(j��)��l(f��)չ�ĕr(sh��)�����ǿƌW(xu��)�����l(f��)�]�������ĕr(sh��)�����ǘO���׃?n��i)˂�˼�S��ʽ��������ĕr(sh��)�����DŽ�(chu��ng)�����I(l��ng)δ���Ͳ���׃��l(f��)չ���r(sh��)�����S��Ӌ(j��)��C(j��)���g(sh��)���ռ����˂��_ʼ���ճ�����������Ӌ(j��)��C(j��)���g(sh��)��������Լ���ɹ������@�Ӳ��H�������Ч�ʣ�߀���Ա��C�����|(zh��)�������_(d��)���°빦����Ч�����N�N�E�����������(hu��)����Ӌ(j��)��C(j��)���g(sh��)�����I(l��ng)���M(j��n)���˿�ǰ��l(f��)չ�r(sh��)�ڡ�
���(xi��ng)�W(xu��)�g(sh��)���}
- �y(c��)�L���̎�
- Փ�IJ��ؽ���
- �����t(y��)�W(xu��)sci����(w��)
- SCI����
- EI��(hu��)�h����(w��)
- SCI�օ^(q��)
- EI�l(f��)��ָ��
- sci���όW(xu��)
- SCI��(r��n)ɫ
- ����(n��i)EI�ڿ�
- SCI�W(xu��)�ƴ�ȫ
- ���HӢ���ڿ�
- SCIՓ��Ҫ��
- ���HӢ���ڿ�
- ��ľ�Q�u(p��ng)��
- һ�^(q��)sci�ڿ�
- �����ڿ�Փ��
- ��ͨ�\(y��n)ݔ
- ����Փ���ڿ�
- sci�ڿ�Փ��
- ����Փ�İl(f��)��
- ��(j��)�Q����
- �˹�����Փ��
- SCIՓ����ԃ
- Փ�İl(f��)��Ҫ��
- ���������Q
- ����W(xu��)Փ���ڿ�
- Փ�Č�����
SCI�ڿ�Ŀ�
���T�����ڿ�Ŀ�
SCIՓ��
- 2024-04-01ANNALS OF PHYSIC���·օ^(q��)�ǎׅ^(q��)
- 2022-11-10ssci��Ͷ�嵽�l(f��)��Ҫ���?
- 2023-07-06��ʿ��SSCI�ڿ��l(f��)��Փ�Ľ�(j��ng)�v��Ҫ
SSCIՓ��
- 2023-12-25AHCI�l(f��)��Փ����W(xu��)�g(sh��)�ɹ���
- 2023-06-14�l(f��)ssciՓ���ܲ鵽���ԃ����
- 2023-08-24Փ�İl(f��)����ÿ��Ա�ssci���
EIՓ��
- 2023-02-07ei��(hu��)�h��ǰ����_ʼ����
- 2022-12-07ei�ڿ�Փ�İl(f��)�����y�Ȇ�
- 2023-06-28ieee xplore ��ei�z����
SCOPUS
- 2023-04-12scopus��(sh��)��(j��)�������Щ�T��īI(xi��n)
- 2023-03-20scopus��(j��)�z���������
- 2023-03-28scopus�����Щ�W(xu��)�Ƶ��ڿ�
���g��(r��n)ɫ
- 2023-05-09������P(gu��n)����������ô���g��Ӣ��
- 2023-05-11�����t(y��)�W(xu��)sciՓ�ĝ�(r��n)ɫ���Æ�
- 2023-05-06����y(c��)��������ô���g��(r��n)ɫ
�ڿ�֪�R(sh��)
- 2015-06-05�l(f��)���ڽ�����µĺ����ڿ�
- 2022-04-02Փ��������l(f��)��Ҫ��������
- 2020-08-05sciՓ����ô��
�l(f��)��ָ��(d��o)
- 2018-03-17��������������ڿ���ÿ���
- 2020-07-28�R������Փ�İl(f��)���x������
- 2022-03-15����ͯ�����Ѱl(f��)���^��Փ��