���f�h����������g�о��Mչ�c����
�r�g��2022��02��13�� ����ƌW���gՓ�� �Δ���
����ժҪ�����,���I���W�İ�ȫ�¼������l�l,�����ǹ��I����ϵ�y(industrialcontrolsystems,ICS),��ʾ��ĿǰICS���ѽ������^��İ�ȫ�[��,������Щᘌ�ICS��ȫ�[���Ĵ���������ͷ�����������Ҫ�����f�h�M�з���.Ȼ��,ĿǰICS�д����˽�й��f�h�������c��ͨ���W�f�h��ȫ��ͬ�ĵ�������,��Y�����ֶξ��ȡ������Եȷ���,����ᘌ����W�f�h������������gͨ�����o��ֱ���m���ڹ��f�h.���,ᘌ����f�h������������g�ѽ��ɞ������W�g��ͮa�I����о����c.���ȽY��2�N�����f�h,��������Ϳ��Y�˹��f�h�ĽY������.���,�o���˹��f�h����������,���������˻��ڳ�����кͻ��ڈ������еĹ��f�h���������ܵ����c,�����Ώ��˙C���c�̶Ⱥͅf�h��ʽ��ȡ��ʽ�@2���Ƕ�,���cᘌ����ڈ������еĹ��f�h���������M��Ԕ���U���͌��ȷ���.���̽ӑ�ˬF������������������c������,�������f�h����������g��δ���о������M��չ���c����.
�����P�I�~���I����ϵ�y;�f�h����;���I���ƅf�h;��������;���lʽҎ�t
�����S�����I���ֻ����W�j�������ܻ��Ŀ��ٰlչ,���I���W�ѽ��ɞ�������M�������Ҫ���A�Oʩ,�䰲ȫ���}Ҳ��u�ܵ���ҕ,�����ǹ��I����ϵ�y(industrialcontrolsystems,ICS)��ȫ�ѳɞ錍ʩ���쏊���;W�j�������Ե���Ҫ����[1G2].Ȼ��,�����l�l��ICS��ȫ�¼�����ICS�ѽ����ڴ�����ȫ©�����[��[3G4],��2017������m�����_˹�ȶ������y�С������ͨ��ϵ�y������Petya���������u��,2019��ί����������늾W����,2021�����ʇ����F·ϵ�y���ܾW�j���ֵ�[5].ICSͨ�^���еĹ��I���ƅf�h(���Q“���f�h”)���F���M���g��ͨ��,�M�����ƹ��ؾW�j�ȵĸ��N�����O��.Ȼ��,�����̘I�ԺͰ�ȫ�Ե�ԭ��[6]��
��������������O��S�̶����ṩ���_�f�h�ęn,���ICS�д��ڴ���˽�С��ǘ˜ʵĹ��f�h[7],��ICS�ľW�j�О������ģ���yԇ[8]�����֙z�y[9G11]�����˾�����.�f�h����(protocolreverseengineering,PRE)��ָ�ڲ���ه�f�h��������r��,ͨ�^���f�h���w�ľW�jݔ��Mݔ����ϵ�y�О��ָ����������M�бO�غͷ���,��ȡ�f�h�Z�����Z�x��ͬ����Ϣ,�Ķ��Ɣ��δ֪�f�h����Ϣ��ʽ�͠�B�Cģ�͵��^��[12].�����PRE���g��ȫ�����˹������ķ�ʽ�M��,��Ҫ���M�����r�g�;���.
������������PRE�ھW�j���֙z�y����Ȕ�����������ģ���yԇ���I����Ч���@��,��u���l�����W���о�,PRE���gҲ��˵õ�Ѹ�ٰlչ,�������“�˹�����”�^�ɵ�Ŀǰ��“�Ԅӻ�����”,����u�lչ��2����֧[12G13]:��һ����֧�ǻ��ڳ�����еąf�h����������g,ͨ�^�Oҕ�f�h���w����Ϣ��̎���^���Լ�����ϢƬ�ε�ʹ�÷�ʽ,�ԫ@ȡ�f�h�ĽY�����ֶ��Z�x,����2007��Caballero�������Polyglot[14],���ڄӑB���c���g��Ɍ��f�h��Ϣ���ֶ΄��֡�
������һ����֧�ǻ��ڈ������еąf�h����������g,ͨ�^���W�j�ȵ�Ŀ�ˈ��������M�з���,�ԫ@ȡ�f�h�ĽY�����ֶ��Z�x,���S����Ȼ�Z��̎�����C���W�����˹����ܼ��g�IJ������,�@f�h����������gҲ�õ���Ѹ�ٰlչ[15],���H�о�������ı��f�h�Uչ�����M�ƅf�h,���ҷ������Ҳ�����S��,����������бȌ���Discoverer[16],NetZob[17],MSAGHMM[18]�ȷ���,���ڸ���ģ�͵�Biprominer[19],ProGraph[20],HsMM[21]�ȷ���,�����l������AutoReEngine[22],SPREA[23],HIERARCHICALCSP[24]����,�����Z�x������FieldHunter[25],WASp[26]�ȷ���.����,�f�h�����������Ҳ��������ֶ΄��ֺͽY���R�e��u���Z�x�Ɣࡢ��B�C�ؘ���չ,��PETX[27],ReverX[28],BFS[29]�ȷ���.Ȼ��,����ڻ��Wϵ�y,ICS�������O��IJ������Ⱥ�푑��ٶ�ͨ��Ҫ�����,����Щ�ӹ����O���Ӌ�����܅s��������,�y��̎���^����s�Ĺ���ָ��͔���[1,3].
�������,���˱��CICS�Č��r�Ժͷ�����,���f�hͨ�����ö��M�ƾ��a,���ҹ��������̶�,�Y��Ҳ���^����,����ֻͨ�^һ����ׂ�������ʾ��������,����Ŀǰ�����ᘌ����W�f�h��������������o��ֱ���m���ڹ��f�h[12,30],��ͬ�r���f�h���@Щ����Ҳ������������ṩ��һ������.�Y�Ϲ��f�h�Ĺ�������,�����겻���ЌW���ڻ��W�f�h����������g,���ᘌ����f�h�������������.
����һ����,���W���ڳ�����Ќ����f�h�M���������,����2018��κ����[30]��Chen����[31]�քe���������c�������g,���F�����f�h���ֶ΄��ֺͽY���R�e,�������^�ߵ��R�e�ʴ_��,�������@�����ICS�ķ�����Ӱ푺Ϳɿ���Ҫ���^��,�Ҍ�ʩ�ͷ����y��Ҳ�^��,����Ŀǰԓ������о��������^��.��һ����,���W���ڈ������Ќ����f�h�M���������,����Ҫ�֞�2���:
����1)��Ҫᘌ����W�f�h����������g�M�и��M�������OӋ,�Ԍ��F���f�h���Ԅӻ��������,����Wu����[32]ͨ�^pairGHMM���������бȌ��㷨�M�и��M,�����������ֶεČ���,��߹��f�h��ʽ��ȡ��Ч�ʺ͜ʴ_��,Wang����[33]ᘌ�����NGgramģ�͵ąf�h������������M�и��M,���VGgramģ�͌��f�h�ֶ��R�e������ߵ�“���ֹ�”.Ȼ��,�@����mȻ���܉F���f�h��ʽ���Ԅӻ���ȡ,��ֻ���^�ٷ����܉��Mһ����ɹ��f�h�ֶε��Z�x�Ɣ�.
����2)�������ҵ����֪�R,���F�й��_���f�h���P�I�ֶ������M�з���,�w�{�������ֶε�“���lʽҎ�t”,����ǰ���F�������P�I�ֶε��R�e,����MSERA[34],IPART[35],IPRFW[36]�ȷ���,�@��˙C�fͬ�ͷ������H�܉��Mһ����߹��f�h��ʽ��ȡ��Ч�ʺ͜ʴ_��,����߀�����ڹ��f�h�ֶε��Z�x�Ɣ�.�C������,���Č�ϵ�y���о��ͷ���Ŀǰ���f�h������������g,��Ҫ����֞�ɴ��:���ڳ�����еķ������g�ͻ��ڈ������еķ������g.�����c����“�˙C���c�̶�”�����ڈ������еķ����֞�ȫ�Ԅ��ͷ������˙C�fͬ�ͷ���.���w����4�c����:
����1)���cᘌ�2�N�����f�hModbus��DNP3�ĽY�������M��Ԕ������,�M���w�{���f�h�Ĺ�������;2)�U��“���ڳ������”��“���ڈ�������”�@2�N���f�h���������ܵĻ��������c���c,���Ķ����Ƕ�ȫ��ӑՓ���Կ����“���W�f�h�����������”��“���f�h�����������”�ą^�e;3)�քeᘌ�“���ڳ������”��“���ڈ�������”�Ĺ��f�h�����������չ�_��������,�����c��“�˙C�fͬ�̶�”��“�f�h��ʽ��ȡ��ʽ”�@2���Ƕ�,�����ڈ������еĹ��f�h������������M�з��ӑՓ�c���ȷ���;4)ӑՓ�ͷ���Ŀǰ���N���f�h����������������c�Ͳ���,���Mһ��������չ�����f�h����������g��δ�����ܰlչ����.
����1���f�h������������
��������ڻ��W�f�h,�mȻ���f�hĿǰ�ԛ]�нyһ���OӋҎ��,������ICS�ĸ߾��ȡ��ߌ��r�Ժ߿ɿ��Ե�Ҫ��,�Լ��ӹ����O����������Ӌ������,ͨ�����f�h�ĽY�����Ӻ���,���ܸ��ӹ̶�[35G36].���,ᘌ����f�h�ĵ��������M�з����͚w�{,���dz������ڹ��f�h�������о�[37].
����1.1�����f�h����
����Ŀǰ���^��Ҋ�Ĺ��_���f�h��Ҫ����:���ؘ˜ʅf�hModbus�����I��̫�W�f�hEthemet�MIP��ݔ���ͨ�Ņf�hIEC104�MIEC61850ϵ�Ѕf�h�ء��ֲ�ʽ�W�j�f�hDNP3���_��ʽ���r��̫�W�f�hEtherCAT[38]��,���������cᘌ�Modbus��DNP3�@2�N���乤�f�h�ĽY�������M�з���[39G40].1)ModbusModbus��1979��Modicon��˾��ɾ���߉������(PLC)ͨ�Ŷ������һ�N�_�Ŵ���ͨ�Ņf�h,�������ڹ��I�W�j�����ڲ���͔Uչ,Ŀǰ���V������,���ɞ鹤�I�I��ͨ�Ņf�h�ĘI��˜�[39].
����Modbus�f�h��һ�N����“���M�ļܘ�”�ąf�h,����Modbus���c֮�g���аl��Ո����xȡ푑���͵���Ϣͨ��,��һ�������·��ͨ��ֻ��̎��247����ַ,�����˿����B�ӵ�����վ�c�ďęC����(Modbus�MTCP����).Modbus��Ϣ����“��”�ķ�ʽ��ݔ,ÿ����Ϣ���д_������ʼ�c�ͽY���c,���ڽ����O���R�e,��Ŀǰ�����е�Modbus���F���ǹٷ��˜ʵ�׃�w,�������_ʼ�M�Y����־��У�ģʽ��ʽ�ȷ��涼����һ���,Ҳ�M�����²�ͬ�����̵��O��֮�g���ܟo�����_ͨ��[41].
����Ŀǰ��Ҋ��Modbus�f�h׃�w��Ҫ����3�N:ModbusRTU,ModbusASCII��Modbus�MTCP.����,Modbus�MTCP����TCP�MIP�_�l,���I�O��ͨ�^��̫�W�M�Д�������,�䔵������ʽ�cRTU�dz����,��ȥ�����е�У�a,��˴�̎�H���c��BModbus��RTU��ASCII�f�h.
������ModbusRTUModbusRTU��һ�N���ö��M�ƾ��a��Modbus���F��ʽ,�Y�������o��.��RTUģʽ��,������Ϣ���������һ���B�m������ݔ,���Ҳ�ͬ����Ϣ��֮�g������Ҫ����ݔ3.5B����Ҫ�Ŀ��e�r�g,���С��ԓ�r�g,�����O���������Ϣ����ǰһ��Ϣ�������m.ModbusRTU����CRCУ�a,�Ա��C��Ϣ��ݔ�Ŀɿ���.
�����ڸ�ʽ����,ModbusRTU��Ϣ����Ҫ����4���ֶ�:�O���ַ�����ܴa��������CRCУ��ֶ�.����,��ʼλ�ͽY��λ�քe��ʾ3.5B���ϵ���Ϣ�g���r�g;“�O���ַ”��ʾ�ęC��ַ,����Ҫ��ԓ��Ϣ�M�лؑ��ďęC,������ԓ��ַ�ďęC���Բ��ؑ�;“���ܴa”��ʾ���w����,����“06”����“������”;“����”������Ҫ�����ľ��w����;“CRC�z�”���ڙz�ԓ��Ϣ�ڂ�ݔ�^�����Ƿ���e,��Ҫ����ǰ3���ֶ�Ӌ��������CRC�z�a.
������ModbusASCIIModbusASCII��һ�N����x�ġ����L�ı�ʾ��ʽ,���ڇ��ȹ��I�����к��ٲ���ASCII�a����˜�,����ModusASCII�ڇ��ȵĹ����I���\�ú���.��ModbusASCIIģʽ��,ÿ���ֹ�������ֳ�2��ASCII�ַ��M�аl��,��2B,�����l������RTUģʽ��2��.ModbusASCII��Ϣ��ͨ�^�ض��ַ��ж���ʼλ��,��Ӣ��ð̖“:”(3A)��ʾ�_ʼ,��“��܇”(0D)��“�Q��”(0A)��ʾ�Y��,��ռ1B��2B.
��������,“��������”��ʾ���m“����”�ֶ��е��ֹ�����,�����ֶκ��x��RTUģʽ���.2)DNP3DNP3�f�h��һ�N�ֲ�ʽ�W�j�f�h,��Q��SCADA�ИI�Ѕf�h���s���]�й��J�˜ʵĆ��}.SCADA����ͨ�^ԓ�f�h�c��վ��RTU��IED�M��ͨ��,ᘌ�늴Ÿɔ_��Ԫ���ϻ��Ȑ��ӭh������һ���ɿ���,��ͨ�^CRCУ�C�����Ĝʴ_��.ĿǰDNP3�f�h�яV�������ڸ��ICS��,�������ˮ̎�����ИI[40].DNP3�f�h��ȫ����TCP�MIP,���������OSI�ąf�h���Y��[42],��Ҫ���������·�ӡ���ݔ���ƌӺ͑��Ì�,�Ҹ��Ӕ�����Ԫ�ĽY�������������.���,��̎�H�Ԕ����·�ӵĔ�����Ԫ����,����DNP3�f�h���ĵĽY��������
����1.2���f�h����
����ͨ�^��ModbusRTU,ModbusASCII��DNP3�ȵ����f�h�ĽY�������M�з���,Ŀǰ�@Щ���f�h�mȻ߀�]�нyһ���OӋҎ��,���ھ��a���Y���������Եȷ��涼����һЩ��������[43],��Ҫ����7�c:
����1)���M�ƾ��a.�鱣�CICS�ĸߌ��r�ԺͿ�����,���f�hͨ��������,����������ö��M�ƾ��a,��������ASCII�M�о��a.
����2)�Y������.��ʹ���ֹ��f�h����“�f�h��”�Ķ��ӽY��,��DNP3,S7Comm�f�h��,��ÿһ�Ӆf�h�Ĕ������ĽY�����^�麆��,���������̶�,�L�ȱ��^��,���w�ʬFһ�N“��ƽ��”�ĽY��,ֻ�����^���͔���,���Ҹ��ֶ�֮�g�]���~����P�I�ֻ�ָ���.
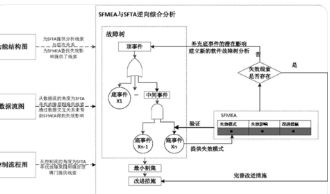
����3)�ֶξ����^��.���f�h�ֶεĄ����w����ͨ���^��,�mȻ�ֶ��L��ͨ����һ���ֹ���������,���ֶȵĹ��܄��ֿ��ܕ����_��Bit��,����DNP3�Ŀ����ֶ�.Fig.5Frameworkofindustrialcontrolprotocolreversebasedontaintanalysis�D5�������c�����Ĺ��f�h������4)�����ԏ�.���f�h���Ă�ݔͨ���������^����������,�e�ǽ�����Ϣ�Ϳ�����Ϣ,����ͬ��ͅf�h�������L�Ⱥ�ʽ�������������.
����5)��ʼ��־���@.���f�h�������������@����ʼ��־,ͨ������“�r�g�g��”����“��־λ”�ȷ�ʽ.6)���eУ�.���˱��C��������ݔ�����_��,��������f�h������“���eУ�”�ֶ�,ͨ������CRC����LRCУ�.�����ֻ���TCP�MIP��̫�W�Ĺ��f�hͨ��������TCP�MIP���·��У�C�Ɓ�У�ֽM���Q�Ĝʴ_��,��Modbus�MTCP.
����7)��B�C����.ICS��ͨ�������C�l������,�ęC푑�����������,ͨ��ģʽ�^�麆��,���,���f�hһ��ֻ�к��εĠ�B�C.ᘌ����f�h���@Щ��������,һ����,���Ի��ڻ��W�f�h�������������,�Mһ�����M�������OӋᘌ����f�h���Ԅӻ������������;��һ����,Ҳ����ͨ�^���ҷ���,�w�{���f�h���N�����ֶε�“���lʽҎ�t”,���Mһ����߹��f�h���������Ч���͜ʴ_��.
����2���f�h����������
�������f�h����������g���������f�h�����g�ڹ����I��ľ��w����[44],���]�н��v�����“�����˹�����”���A��,Ŀǰ��Ҫ�֞�2�N��ʽ:“���ڳ������”��“���ڈ�������”�Ĺ��f�h����������g[15,45].
����2.1���ڳ�����еķ������
�������س���������g,�f�h�����в�ͬ�ֶ�ͨ���������Եĺ����{��,������ͬ����ͨ��Ҳֻ�{����ͬ�ֶεĔ���.���,���ڳ�����еĹ��f�h����������g����ͨ�^��ۙ������Ŀ�˹��f�h����������g�����ї���ָ�����С��������Ĵ�������Ϣ��׃����r,����ɹ��f�h���ֶ΄��ֺ��Z�x�Ɣ�[46],�����f�h�ĽY�������������ԏ�������Ҳ�����������@����Č�ʩ.
����Ŀǰᘌ����f�h���������Ҫ�ǽ���“���c����”˼�댍�F,���֞�“�o�B���c����”��“�ӑB���c����”,�����ą^�e��Ҫ�����Ƿ���Ҫ�\�г���.ǰ�߿��Բ��\�г���,�H��Ҫ������Դ���a�M�з���[47];��������Ҫ�\�г���,ͨ�^�{ԇ�����aע��ȷ�ʽ[48]��Ŀ�˳����M�з���[49].�������ڹ��س���Դ���aͨ���^�y�@ȡ��ԭ��,Ŀǰ��������ǽ���“�ӑB���c����”���F�����س�����ָ��͔����ĸ�ۙ�c����[50],��Ҫ�֞�Ŀ�˱O�ء�Ŀ�˸�ۙ�c�����ͅf�h�Ɣ�3���A��[51].
��������,�_���ɱO�ص�Ŀ�˅f�h����,������M�Ƴ����f�h��������O��Ŀ��;Ȼ��,ͨ�^�ӑB���c���������c�嘶���g��ۙ��ӛ�Ŀ�˳����\�����g�ĺ�����ָ����ֶΔ����Ĉ���܉�E;���,�Y������֮�g��“���F”��r,����,ijЩ�f�h�����ֹ�����Щ�����г��F����ijЩ�����Ķ��M��ָ���{���^��Щ�f�h�ֹ�,�M���Ɣ�����f�h�ֶε�߅��,���Y�Ϲ��f�h�ֶε�����,�Mһ����ɹ��f�h���ĵĸ�ʽ��ȡ���Z�x�Ɣ༰��B�C�ؘ�.
����2.2���ڈ������еķ������
�������ڈ������еĹ��f�h����������g��Ҫᘌ����f�hͨ�Ō��w�g�ľW�j���������M�з���,���c�Y�Ϲ��f�h������,ͨ�^���бȌ�������㷨��Ʌf�h�ĸ�ʽ��ȡ�Ȳ���.�����@����H��Ҫ�ռ��ͷ������w�g��ͨ������,���H���ڌ�ʩ,���Ҍ�Ŀ��ϵ�y�ķ����Ե�Ӱ푶����^С,��˳ɞ�Ŀǰ�о��^��ķ���.
����ԓ��g�Ŀ�����̻�������ڻ��W�f�h����������g[52],�����˸��õ��m���ڹ��f�h,���W�ߌ����f�h�Ĺ����������뵽ԭ�еĻ��W�f�h����������,���M�������OӋ�˹��f�h��������IJ��֭h��(���ʽ��ȡ),�γ�һ�N“ȫ�Ԅ���”�Ĺ��f�h����������g,�����^�ߵ��Ԅ��Ժ�ͨ����.
��������һ���W���ڹ��_���f�h�и��N�P�I�ֶε�����,�w�{��������“���lʽҎ�t”,��ͨ�^“�˹����A”�ķ�ʽ��ǰ�R�e˽�й��f�h�еIJ����P�I�ֶ�,���Mһ����ߺ��m��������h����Ч�ʺ͜ʴ_��,�M���γ�һ�N“�˙C�fͬ��”�Ĺ��f�h����������g.��ֵ��ע�����,�@2��g���nj��о����ļ����ڹ��f�h��“��ʽ��ȡ”�A��,�e���P�I�ֶεĄ���,���ԓ�A�εĜʴ_��ֱ���Pϵ�����m“�Z�x�Ɣ�”��“��B�C�ؘ�”�Ĝʴ_��[53].
�������ڈ������еĹ��f�h����������g��Ҫ����ݔ���A̎������ʽ��ȡ���Z�x�Ɣ�͠�B�C�ؘ�4���A��[15],����,��ʽ��ȡ�����Mһ���֞��ֶ΄��ֺͽY���R�e.��1�A����ݔ���A̎��.���ȸ���Ŀ�˅f�h���w�������W�j���������M���^�V,���֞鲻ͬ�ĕ�Ԓ;Ȼ���ٽY�Ϲ��f�h�Ļ�������(������L�ȡ��������ƶȵ�),��Ŀ�ˈ��������M�г������,�õ���M�������м���.
������2�A���Ǹ�ʽ��ȡ,��Ҫ�����ֶ΄��ֺͽY���R�e2�����E.�����ÿ�Mͬ��͵Ĉ������м���,�Y�Ϲ��f�h�P�I�ֶε�����,ʹ�����бȌ����yӋ����������ģ�͡���ȌW�����㷨,��ɹ��������ֶεĄ���;�����cͨ�^���N����㷨,��ɹ��f�h�ĽY���R�e.
������3�A�����Z�x�Ɣ�.ᘌ�ÿ�������ͬһ�N�f�h�Y��,�Y�Ϲ��f�h���N�P�I�ֶε�����(��λ�á��L�ȡ���ֵ���ص�)����������Ϣ,�Ɣ������ֶε��Z�x.���ԓ�A��ͨ��Ҫ���f�h�đ��ñ������OӋҎ�������֪�R����һ���˽�,������Ŀǰ���f�h�I����ȱ�ٽyһ���OӋҎ��,���Ҹ����؏S�Һ��ٹ��_���Եąf�h�ęn,���]���������֪�R,ʹ���Z�x�Ɣ���Ȼ�ǹ��f�h����������y�c.
������4�A���Ǡ�B�C�ؘ�.��Ϣ��������ͨ������һЩ�܉�ӳ��Ϣ��B�Ġ�B�ֶ�,������ͬ��Ϣ�Ġ�B�ֶ�ȡֵ�����Ϣ֮�g�����,������ɠ�B�C����,�S�����Mһ����ɠ�B�C����.����һ��������ԓ�A�α��^��ه��ʽ��ȡ���Z�x�Ɣ�ĽY��,��һ����,���ڴ�������f�hֻ�к��εĠ�B�C,����Ŀǰᘌ����f�h��B�C�ؘ����о�Ҳ���^��.
�������ڈ������еąf�h����������gͨ�������Ęӱ��ĸ��w�ʺͅf�hҎ�������֪�R����һ��Ҫ��,���,���ڷ������^����ȱ�مf�h�OӋ���֪�R��ICS���f,ᘌ����f�h�M����������Ծ���һ���y��.��2�քe��5���ǶȌ����cͬ��ͻ��W�ąf�h����������g�M�Ќ���.
����2.3�Y
�����������c�U����“���ڳ������”��“���ڈ�������”�@2��f�h���������ܵĻ��������c���c,���Ķ����ǶȌ����f�h����������g�cͬ��͵Ļ��W�f�h����������g�M�Ќ��ȷ���,���Y���Եă��ݺ����.���,ᘌ����f�h����������g,�Mһ������“���ڳ������”��“���ڈ�������”�@2������g�ă��ݺ����,�������@�������ڈ������е�����������g�������ڌ�ʩ,�Ҍ�ICSӰ��^С,���Ŀǰᘌ�ԓ��g���о����^��,��ּ���Mһ����ߌ����f�h���R�e���Ⱥ͜ʴ_��.
����3���ڳ�����еĹ��f�h����
����������2���ķ���,���ڳ�����еĹ��f�h����������gͨ�^��ۙ������Ŀ�˹��س���������gָ�����С��������Ĵ�������Ϣ��׃����r,���F���f�h�ĸ�ʽ��ȡ���Z�x�Ɣ�,���Ҵ������������ǽ���“���c����”��˼��,��Polyglot[14],AutoFormat[54],Prospex[55]��.
����2018��κ����[30]�����һ�N�����o�B���M�Ʒ����Ĺ��f�h��������,��“���c����”˼�둪�����o�B���M�Ʒ����^��[47,56],��Ҫ���������A̎�����������÷������f�h���ؘ����Z�x��ȡ4���A��:1)�xȡIDAPro���R����ąR�����a,��ͨ�^“���a��������”��“Դ�ڄӑB���c�Ĕ�����������”���cͨ���^�̟o�P�ĺ���;2)�{��IDC����,�@ȡ����������Ϣ�ͺ����g����ه�Pϵ,���Ɣຯ�����;3)����ǰһ�A���Ɣ�Y��,�Дຯ�����a����,��Ɍ�Ŀ�˅f�h�����ؘ��c���,�γ�ӛ䛳����ֶνY���ͳ����ֶ�ֵ�Ď��Y��;4)ᘌ����f�h���ֶε�����,��У����ֶ�ͨ�����S������λ�\��,��Ʌf�h�����Z�x��Ϣ��ȡ.
����4���ڈ������е�ȫ�Ԅ����f�h����
��������ڻ��ڳ�����е�����������g,���ڈ������е�����������g�����ڌ�ʩ,�Ҍ�ICS��Ӱ��^С.��˲��W�ߌ����f�h�Ĺ�����������F�еĻ��W�f�h����������,�����c��“��ʽ��ȡ”�h���M�и��M�������OӋ,ʹ������m���ڹ��f�h,�γ�һ�N“ȫ�Ԅ���”�ķ������g,��ȫͨ�^�C�����߃Hͨ�^�������˹��f��,��Ɍ����f�h���������[57].���¹���Ҫ����“��ʽ��ȡ”��ʽ�IJ�ͬ����֞�4�[15]:�������бȌ��ķ����������l�����ķ��������ڸ���ģ�͵ķ����ͻ�����ȌW���ķ���
����5���ڈ������е��˙C�fͬ���f�h����
�������ڈ������е�ȫ�Ԅ����f�h����������g��Ҫ�Y�Ϲ��f�h�Ĺ�������,��ȫͨ�^“�C��”����������“�˹��f��”���F�����f�h���Ԅӻ��������,����һ���W�߽Y����֪���f�h�и��N�P�I�ֶε�����,�w�{��������“���lʽҎ�t”,����“��ʽ��ȡ”�A��ͨ�^“�˹����A”�ķ�ʽ��ǰ�R�e˽�й��f�h�еIJ����P�I�ֶ�,���Mһ����ߺ��m��������h����Ч�ʺ͜ʴ_��,�M���γ�һ�N“�˙C�fͬ��”�Ĺ��f�h����������g[72].���¹���Ȼ����“��ʽ��ȡ”��ʽ����֞�4�:�������бȌ��ķ����������l�����ķ����������Z�x�ķ����ͻ��ڔ��������ķ���.
����5.1�������бȌ��ķ���
����2021��Wang����[34]�J��“��ˮ��ʽ”�Ă��y�f�h�����o���������A���R�e����Ч��Ϣ������ǰ���A��,�����˹��f�h����Ĝʴ_��.,���,�īI[34]���һ�N���A�μ������������———MSERA,�����OMRON_FINS,BACnet��Heidenhain�ȶ�N���f�h���������.ԓ��������ͨ�^���f�h�и��N�����ֶε�“���lʽҎ�t”,��ǰ�����N�����ֶεķ������Z�x�M���A�ھ�,��f�h���R��������̖��λ�Ø��R����,�������“�Z�x���ȼ�”��Q�����ֶε�“�Z�x�دB”���};Ȼ�����Ɣ�ĽY��������m������h��,ͨ�^���бȌ��㷨��DBSCAN����㷨[73]�������ƶȷֽM���֞�ͬһe,�������ֶεĄӑB׃������,��ͬһe�еĔ��������֞��ֶ�;���,�ٌ��o��ͨ�^�A�ھ�õ����ֶ��Z�x�M�����·���.
��������,߀ͨ�^“�ֶ�У��”������һЩ�����ֶ��M��������.MSERA����ͨ�^“���lʽ�R�e+�C���R�e+����”�ķ�ʽ,�_���܉���߹��f�h����Ĝʴ_��,���Ǯ��B�m�����ֶεă��ݛ]�и�׃�r,MSERAҲ���y�^�ֳ��@Щ�ֶ�,�@Ҳ�ǻ��ڈ������еąf�h����������g�o���˷��Ĺ������y.
����5.2�����l�����ķ���
����2014��Zhang����[74]�J����������������B�m���F���l�ʱ��^��,��������m�ֹ����кܸߵĿ�׃��,�tԓ�����кܿ�����һ���P�I�ֶ�,��������Prowork����,ʹ��ͶƱ����(votingexpert,VE)�㷨[75]�Ɣ��P�I��߅��,�����������(���L�ȡ�ƫ�������l��)�����x�P�I�ֶ��M���R�e.����,VE�㷨���B�m������ʹ�ô��ڻ���,��ͨ�^�Q��Ҏ�tC(x)��ÿ�����E���x������ܵĆ��~߅��,���ڷָ�]�зָ������ı�,��˷dz��m���ڶ��M�ƅf�h���ֶ΄���.
����6ӑՓ
����6.1�������ȷ���
��������ڻ��W�f�h,���f�h�mȻ�]�нyһ���OӋҎ���ʹ��������֪�R,���´�������W�f�h������������o����ȫ�m��,���������нY�������������ԏ��ȹ�������,�鹤�f�h����������ṩ�˸�������.�Y�Ϲ��f�h�Ĺ�������,Ŀǰ���ڳ�����еĹ��f�h����������g��Ҫ����“���c����”��˼��,ᘌ����س���������g�ĺ�����ָ��͔�����܉�E�M�и�ۙ�c����,�܉��_���^�ߵ��R�e���Ⱥ͜ʴ_��,����ԓ�������H��ICS�ķ�����Ӱ��^��,�����ڹ����I���y�Ԍ�ʩ,����Ŀǰᘌ�ԓ������о��Ա��^��.
���������ڈ������еĹ��f�h������������H��Ҫ�����@�ľW�j�����M�з���,�mȻ�R�e���Ⱥ͜ʴ_�Ȳ�����ڳ�����еĹ��f�h�����������,���������ڌ�ʩ�Ҍ�ICS��Ӱ푱��^С,�Ԅӻ��̶�Ҳ�����^��,��˳ɞ�Ŀǰ�о��^��ķ���.�������c�����˙C���c�̶ȵIJ�ͬ����֞�ȫ�Ԅ��ͺ��˙C�fͬ��,�ٰ��ո�ʽ��ȡ��ʽ��ͬ,�^�m�֞�������бȌ��ķ����������l�����ķ����ͻ��ڸ���ģ�͵ķ�����.����,��5���cᘌ�“���ڈ�������”�Ĺ��f�h�����������,�Ķ����S���M�Ќ��ȷ����c���Y,��Ҫ�����r�g���������ȡ��ֶ΄��֡��Y���R�e���Z�x�Ɣࡢ��B�C�ؘ���.
�������ߣ��S��1,2������1,2����P1ë��1��ռ�S3����4
SCIՓ��
- 2024-09-10sci�ڿ������˾ܽ^�������ɅR��
- 2024-09-10�о������IՓ�IJ����c���ؼ���
- 2024-09-10Advanced Science��픿���
SSCIՓ��
- 2024-09-02���xssci����ČW��ڿ�15��
- 2024-08-31SSCIՓ�ĵ�һ������ʲô����?
- 2024-08-23ˇ�g����Փ�İl�������׆�
EIՓ��
- 2024-08-23���W�I��ei���h���ڿ�
- 2024-08-21�Cе����EI���H���h����Щ
- 2024-08-17ei���hՓ���u�Q�Ѓ��݆�
SCOPUS
- 2024-05-29scopus�����Щ������ڿ�
- 2024-05-09����W�lһƪscopusՓ���y��
- 2024-04-15SCOPUS�z���ĕ��h��ô��
���g��ɫ
- 2024-08-17���H�����ڿ�Ͷ�����L�r�gҊ��
- 2024-08-17���H�����ڿ��u�Q���J��
- 2024-08-17�h��������s־���]
�ڿ�֪�R
- 2024-09-10�@ˇ�W�ƺ����ڿ�Ŀ�
- 2024-09-06һ���������ڿ��քeָʲô
- 2024-08-27�WУ�h���c˼������ׂ�����
�l��ָ��
- 2024-08-17Փ�����S���_�l���
- 2024-08-17ע�ԕ�Ӌ����Փ�Č�ʲô����
- 2024-08-17Փ���}Ŀ��ô���·f��